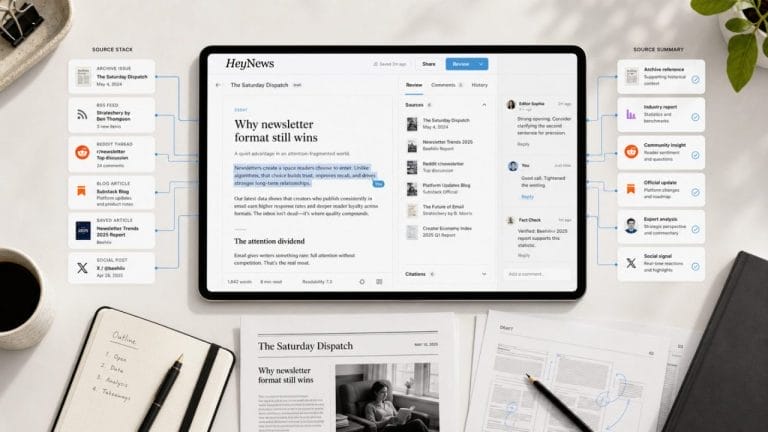
You signed up for ChatGPT Plus eighteen months ago. You built a Custom GPT trained on your last twenty newsletter issues. You wrote a long system prompt that walks the model through your Sunday production session. The setup works. The drafts are usable. You can ship them after a round of edits.
Your newsletter still takes roughly the same number of hours it took before you started.
This is the conversation nobody at OpenAI is going to have with you. ChatGPT is the most successful consumer software product in history. The Stanford AI Index 2026 reports that generative AI reached 53% population adoption within three years, faster than the personal computer or the internet. The product is genuinely good at what it does. It also happens to be the wrong shape for the job you are asking it to do.
Newsletter production is six stages of work. ChatGPT handles part of one of those stages. The other five either continue to live in your browser tabs, or they get solved by something that was actually designed to solve them.
Tomorrow, we open HeyNews to the public after a year of building it for ourselves. Before you start the trial, you deserve the honest technical comparison between a general purpose chatbot and a tool built for newsletter workflows. Here it is.
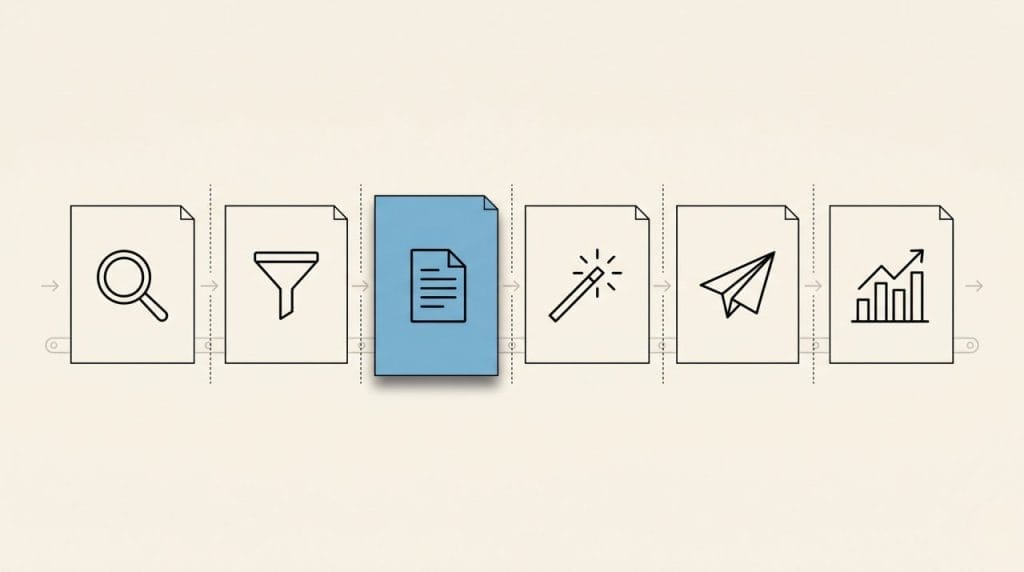
How Many Stages Does Newsletter Production Actually Have?
A newsletter issue is the output of a recurring six-stage process. Each stage does a different kind of cognitive work, and each stage has its own time cost.
Stage 1: Source monitoring. Scanning RSS, social platforms, competitor newsletters, and saved articles for stories worth covering. I broke this stage down in detail two weeks ago as five subtasks pretending to be one.
Stage 2: Story selection. Filtering and ranking candidates against your editorial patterns until you have a final lineup.
Stage 3: Drafting. Writing the actual prose. Introductions, transitions, commentary, the structural connective tissue between stories.
Stage 4: Refinement. Subject lines, preview text, image search, formatting decisions, mobile preview, link checks.
Stage 5: Distribution prep. Final review, test sends, deliverability checks, scheduling.
Stage 6: Analytics feedback. Reading last issue’s open rates, click data, and audience trends, then carrying those signals into the next draft.
ChatGPT enters stage 3. Maybe through a Custom GPT trained on a slice of your archive, maybe through a long system prompt, maybe through pasting your notes and asking for a draft. The output quality is reasonable. The architectural question is what happens before and after the model sees your input.
Before stage 3, you have manually scanned dozens of sources, copied URLs into a doc, summarized each one, and pasted everything into the chat window along with context about your audience, your last issue, and the angle you want this week.
After stage 3, you take the draft out of the chat window, paste it into your ESP, search for images, generate subject lines (in another chat window or another tool), check formatting, send a test, then send to your list. None of those steps happens inside the chatbot.
Roughly 83% of your weekly newsletter workflow lives outside the chat window. The twenty minutes of drafting is the part you celebrated.
That math is generous. For many operators, it is worse.
Why Does ChatGPT Feel Like It Should Work?
The instinct is correct. ChatGPT is a writing tool, and newsletters are, well, all about writing. The instinct stops being correct when you look at how the model is built.
Three architectural facts matter.
Fact 1: Context windows got larger. The model still struggles with the middle. Big numbers do not equal usable memory. A peer-reviewed 2024 study by Nelson Liu and colleagues at Stanford, published in the Transactions of the Association for Computational Linguistics under the title “Lost in the Middle”, demonstrated what they called the U-shaped performance curve. Language models perform best when relevant information sits at the beginning or end of the input context. Information placed in the middle gets significantly less attention, even in models built for long contexts. Pasting your last 50 issues into a session produces a model that paid most attention to issue 1 and issue 50, with the middle 48 fading into the background.
Fact 2: Custom GPTs have hard limits that newsletter archives blow past quickly. OpenAI’s official help center documentation caps Custom GPTs at 20 files for the lifetime of the GPT, with each file limited to 512MB or 2 million tokens, whichever comes first. A weekly newsletter operator publishing for two years has roughly 100 issues. If each issue is one file, the operator hits the 20-file ceiling after five months. The workarounds (concatenating issues into bigger files, summarizing the archive into a style guide, retraining periodically) all add operator time at exactly the moment ChatGPT was supposed to save it.
Fact 3: ChatGPT does not know what you published last week. Memory features have improved. They store preferences and facts across sessions. They do not store full conversation histories. They do not connect to your beehiiv or Kit account. The model cannot read your open rates from last issue. It cannot tell you which sources have produced the most clicked links over the past quarter. The feedback loop between performance and next draft adjustments stays manual, every Sunday.
The summary is that the architecture is generic by design. ChatGPT serves an estimated 800 to 900 million weekly active users running every imaginable use case on the same backend. That generality is what makes the product accessible. That same generality is what makes it the wrong shape for a domain-specific workflow.
Surprising? Only if you have never tried to scale a Custom GPT past month six.
The Prompt Engineering Tax: What ChatGPT Charges in Hours
ChatGPT Plus is $20 per month. The Custom GPT feature is included. On paper, the tool is nearly free compared to anything else in your stack.
The dollar cost is not where ChatGPT charges you.
A 2025 study published on arXiv by Rizal Khoirul Anam surveyed 243 LLM users across academic and occupational backgrounds and found that the structure and clarity of prompts substantially predict output quality. The result is intuitive. The implication is brutal. Every newsletter operator using ChatGPT is paying an invisible weekly tax to engineer the prompt that produces a usable draft. Setup. Refinement. Repair. Every Sunday.
The setup alone is the first big bill. For a typical Custom GPT trained on a newsletter archive, the setup takes five to ten hours. Writing the system prompt. Selecting which issues to upload from your 100. Tweaking instructions after the first three drafts comes back wrong. Iterating on tone, structure, and example handling until the output stops sounding like a press release.
The weekly tax is smaller but recurring. Pasting in this week’s stories. Re-explaining the angle. Adjusting the prompt because last week’s output drifted. Generating subject lines in a separate chat because the model lost track of the voice halfway through. Even with the best Custom GPT setup, most operators spend 20 to 40 minutes per issue on prompt side overhead alone.
ChatGPT is the cheapest line item on your invoice and the most expensive line item on your calendar.
The arXiv study noted that end users frequently submit imprecise prompts and rely on trial and error to find what works. Trial and error is fine when the tool is a research assistant. The same approach gets expensive fast when the tool is supposed to be your weekly production system. The cost of a bad prompt at 10pm on a Sunday gets paid in another forty minutes of editing.
Just math.
What Goes Wrong at the Macro Level When Everyone Uses a General Tool
There is a market-level effect that shows up once enough operators use the same general tool the same way.
Salesforce’s Tenth State of Marketing report, published in February 2026 and based on responses from 4,450 marketers across 26 countries, found that 84% of marketers admit to running generic campaigns even with AI tools deployed. 78% say they need more personalized content than they are currently able to produce. Salesforce’s own marketing CMO Bobby Jania summarized the finding in plain language: most teams are using the most powerful technology in history to send more one way spam, faster.
The newsletter version of this problem is even worse, because newsletters are personal media. The reader subscribed to a voice. Generic AI output diluted across thousands of operators in the same niche reads to the reader as inbox spam with a name on it.
Read that twice.
My cofounder Eren wrote the craft side of this argument last week, when he documented what specifically gets lost when generic AI writes your newsletter. The five erasures he cataloged trace back to an architecture problem. The model quality is fine. The model is doing what it was trained to do. The problem is the job.
What “Purpose Built” Actually Means at the Architecture Level
Wharton’s Ethan Mollick, in Co Intelligence: Living and Working with AI, makes a distinction that maps directly onto this problem. AI works best when you delegate work to it the way you would delegate to a person. Treat it as a search engine you query and the output stays shallow. The delegation gets harder when the AI does not know who you are, what you published last week, or where the stories for this week are supposed to come from.
A purpose built tool inverts the relationship. It does the work that depends on knowing who you are. You do the work that depends on knowing what you mean.
HeyNews was built around that inversion. Three architectural design decisions distinguish a purpose-built newsletter platform from a general-purpose chatbot. None of them is about the model itself. The model is the easiest part. The work is everything around it.
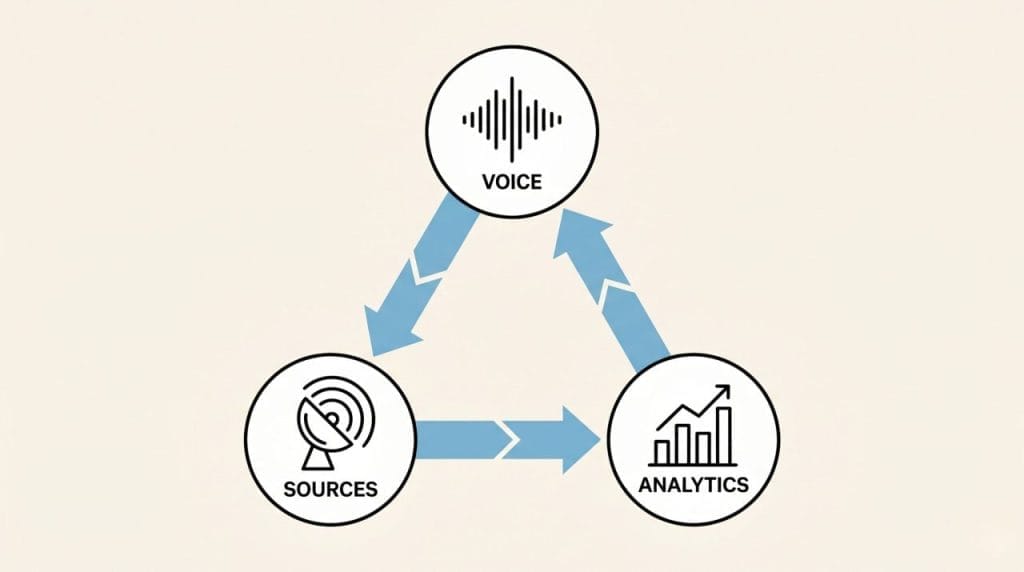
A voice profile that learns from your archive. HeyNews connects to your newsletter platform through native API (beehiiv with an API key, Kit through OAuth) or through any platform with a public archive URL (Substack, Ghost, Mailchimp, Medium, or any host with a public archive). It imports every past issue and builds a voice profile by analyzing your tone, vocabulary, sentence patterns, section structure, and signature phrases. The profile persists across every draft. No re-uploading. No re-explaining. No 20 file ceiling.
Source intelligence that monitors what you already read. The platform extracts every site, feed, and social profile your past issues have ever referenced. It monitors those sources on a schedule and scores incoming stories by relevance to your editorial patterns. When you open Compose, the stories are already there, ranked. Reddit subreddits, RSS feeds, blog homepages, social profiles, saved articles from a Chrome extension. All in one feed.
A performance feedback loop that closes automatically. Once an issue is sent, HeyNews pulls open rates and click data from the connected platform (beehiiv every hour, Kit every six hours) and feeds those signals back into the AI Writer that drafts your next issue. The analytics loop closes on its own. You do not need to read a dashboard, take notes, and remember the lessons next Sunday. The system does it.
The combined effect is that the system gets better the longer you use it. ChatGPT stays the same every week because the model has no idea that anything is changing.
The McKinsey State of AI 2025 report, based on 1,993 respondents across 105 nations, found that AI high performers are roughly three times more likely than their peers to have fundamentally redesigned workflows around AI. The losing pattern is bolting models onto existing processes. Only about six percent of organizations report a significant EBIT impact from AI use. The rest are running pilots that never graduate. The pattern at the org level is the same one at the operator level. Tools layered on broken workflows produce marginal gains. Workflows designed around the tool produce real ones.
Six Stages, Two Architectures, One Honest Comparison
Stage by stage, here is what each path actually delivers for a solo weekly newsletter operator.
Stage 1: Source monitoring. ChatGPT: nothing. You scan sources manually, copy URLs into the chat. A purpose built tool: automatic. Sources extracted from your archive and monitored continuously, with relevance scores on every incoming story.
Stage 2: Story selection. ChatGPT: You summarize each candidate, paste in, and ask for relevance ranking. A purpose built tool: stories ranked against your editorial patterns. A Smart Select button picks candidates by section. You override the picks when the system gets it wrong.
Stage 3: Drafting. ChatGPT: the part it does best. Prompt in, draft out. A purpose built tool: same draft generation, plus a voice profile that does not have to fit inside this session’s token budget. The model in both paths is similar. The context is the difference.
Stage 4: Refinement. ChatGPT: subject lines and preview text usually generated in a separate session. Image search lives somewhere else. A purpose-built tool: subject lines, preview text, image search, Hot Takes commentary, and one-click transforms (shorten, expand, formalize, simplify) all in the same Compose view.
Stage 5: Distribution prep. Neither tool sends your email. This stays with your ESP. A purpose-built tool at least knows which ESP you use and can format the output for clean paste.
Stage 6: Analytics feedback. ChatGPT: you read your dashboard, remember what worked, write a note to your future self. Maybe. A purpose-built tool: automatic.
Five of six stages favor the platform built for the job. The sixth is a tie. A general purpose chatbot is competing for the one stage where it has a model advantage. The other five are won by the tool that was actually designed for the work.
Tomorrow We Launch HeyNews
Tomorrow, HeyNews opens to the public after a year of internal use. My cofounder Eren wrote the longer version of that story last week, including the part where our team produced more than 550 newsletter issues across more than 10 formats with the platform before letting any outside writer try it.
What is available starting May 12: a 14 day free trial that includes 5 generated drafts (whichever runs out first). Three plans. Until June 30, Starter at $49.5 per month for 10 issues and 1 publication. Pro at $149.5 per month for 30 issues across 2 publications. Team at $249.5 per month for 60 issues across 5 publications with unlimited AI revisions. Just use the code WELCOME50 at checkout.
The prices will double after June 30.
You’ll get Native integrations with beehiiv (via API key) and Kit (via OAuth). Public archive import for Substack, Ghost, Mailchimp, Medium, or any host with a public archive URL. Chrome extension for one click article saving. Reddit subreddits, RSS feeds, blogs, and social profiles are supported as sources. Automations to schedule recurring drafts. Multi publication support with separate voice profiles per newsletter.
The proof step is your own archive. Connect it. Generate one draft. Decide from there.
In a Nutshell
- Newsletter production is a six stage workflow. ChatGPT handles part of stage 3. The other five stages either stay in your browser tabs or get handled by a tool built for the job.
- Custom GPTs accept a maximum of 20 files for the lifetime of the GPT. A weekly newsletter operator hits that ceiling after roughly five months. The workarounds (concatenation, summarization, retraining) add the operator hours that ChatGPT was supposed to save.
- Larger context windows do not solve voice fidelity. The Stanford “Lost in the Middle” study showed that LLMs pay most attention to the beginning and end of input context, and significantly less to the middle, even in models built for long context.
- A platform built for newsletter production architectures three things differently: a voice profile that learns from your archive, source intelligence that monitors what you already read, and a performance feedback loop that closes automatically. The system gets better the longer you use it.
- The fastest way to judge any AI tool is your own publication. Connect your archive, generate one draft, read it the way your most discerning subscriber would, decide from there. Tomorrow morning the trial opens.
Most operators keep paying ChatGPT for one reason. The dollar cost is visible on the invoice. The hour cost stays buried inside Sunday afternoons that disappear into prompt rewrites.
Tomorrow we open the trial. Your last five years of issues. A direct API or archive connection. One draft, in your voice, generated against the sources you actually read. 45 minutes of your Sunday spent on review. Production handled by the system.
That is the workflow comparison. The proof is your own publication.
Start your 14 day free trial: heynews.co